
So what’s this project about?
TLDR: We sampled Gen Z males, had them record their voices reading a passage, and asked them to self-rate their sexuality on a 0-10 scale. We’re analyzing these recordings using advanced phonetic tools and plan to build neural networks that predict both self-reported sexuality and listener-perceived sexuality.

Click to expand a longer explanation.
This project explores the acoustic features that correlate with both self-reported sexuality and listener perceptions of sexuality in Gen Z male voices. We recruited Gen Z male participants who recorded themselves reading a passage (found below) and provided self-ratings of their sexuality on a scale from 0 (100% straight) to 10 (100% gay), with 5 being 50-50 bisexual.
The project is currently in the analysis phase, with plans to extend into perceptual studies in CUNY Queens where listeners will rate how "gay" the voices sound. This will give us two different prediction targets to train our neural networks on: self-reported sexuality scores and listener-perceived sexuality scores.
The Passage:
So this morning, I woke up late and immediately stubbed my toe on the dresser — great start, right? I grumbled something half-conscious, grabbed whatever shirt was clean-ish, and headed out. The sky looked weird, like that shade of blue-gray that makes you question if it's about to rain or not. I stopped by the corner store to grab a toasted bagel and orange juice, but they were out of both. The cashier joked, "It's Monday energy," and I half-laughed because, yeah, true. I took a seat near the window, scrolled my phone, and overheard someone say, 'The giraffe exhibit opens at noon,' which felt oddly profound at the time. After a few bites of something vaguely egg-shaped, I wandered to the park. A kid zoomed by on a scooter yelling, 'Zoom, zoom!' like it was a sound effect that summoned speed. I sat under a tree, listened to the breeze, and watched a yellow balloon get tangled in a power line. Weird morning. But honestly? Not the worst.

What makes this approach unique?
TLDR: We’re using a two-stage neural network approach: first, interpretable models using hand-crafted phonetic features (aka, they were previously reported in traditional studies), then high-capacity models on raw audio. This closes the gap between older, linguistic theory and modern AI/ML methods.
Click to expand a longer explanation.
Stage 1: Interpretable Models (Feature → Prediction)
We start with hand-crafted sociophonetic features including fundamental frequency (F0, aka pitch), formant frequencies (the resonant frequencies that give vowels their distinct sound), silibant center of gravity (how sharp or dull "s" sounds are), rhythmic patterns, and pausing behavior. These features are fed into transparent models like logistic regression (a statistical method that finds relationships between inputs and outputs), random forests, or linear SVMs. Using feature importance tools (methods that tell us which measurements matter most for predictions), we can identify which acoustic properties are significant predictors of sexuality perception.
This approach may not achieve state-of-the-art accuracy, but it provides crucial evidence that aligns with linguistic research expectations: "Pitch range and /s/ spectral characteristics are significant predictors of perceived sexuality."
Stage 2: High-Capacity Predictive Models
We then train deep neural networks (complex AI models with many layers) on raw waveforms (the actual audio signal) or self-supervised learning embeddings (pre-trained representations from models like Wav2Vec2, HuBERT, Whisper that have learned to understand speech). These models maximize predictive accuracy on held-out speakers and listeners (people not used during training). To understand what these black-box models (models that work well but don't explain their reasoning) are learning, we employ several probing techniques:
Stage 1.5: Targeted Feature Ablation
Once we identify which interpretable features matter most in Stage 1, we systematically remove them from the neural network's input. This process is called "ablation" - essentially controlled removal to test importance. For example, if /s/ center-of-gravity is important in our interpretable models, we mask sibilant regions (hide all the "s" and "sh" sounds) in the raw audio for Stage 2 models to see how prediction accuracy changes.
This bridging approach gives us both interpretable linguistic insights and high-performance predictive models, allowing us to say: "A black-box model predicts perceived sexuality at X% accuracy, and when we probe it, we find it relies heavily on prosodic features (rhythm, stress, intonation) and sibilants ("s" and "sh" sounds)."
What tools and methods are you using for acoustic analysis?
TLDR: Praat for phonetic annotation, Montreal Forced Aligner for phoneme alignment, and FastTrack for formant analysis. (Possibly more, will update.) This gives us more broad prosodic patterns and segmental details as well.
Click to expand a longer explanation.
Praat Phrase-Level Annotations
Praat is the gold standard for phonetic analysis in linguistics research. We use it to extract prosodic features like pitch contours, intensity patterns, and rhythm metrics across entire utterances. This captures the aspects of speech that often carry social meaning. We hand-made phrase-level annotations to feed into the Montreal Forced Aligner.
Montreal Forced Aligner (MFA)
MFA provides precise time alignments between the audio and phoneme sequences, allowing us to analyze specific sound segments. This is crucial for studying features like /s/ spectral characteristics, vowel formant patterns, and consonant-vowel timing relationships that have been implicated in previous research on sexuality perception. The phoneme-aligned textgrids are then fed into FastTrack.
FastTrack Formant Analysis
Professor Santiago Barrera's FastTrack repository offers formant tracking across different speakers and recording conditions. Formant patterns (especially F1 and F2) are key indicators of vowel quality and have been linked to perceived speaker characteristics in sociolinguistic research (especially in diphthongs for previous "gay voice" studies).
What’s next for this project?
TLDR: We’re currently analyzing the acoustic data and preparing to launch listener perception studies. The goal is to train two separate neural networks - one for self-reported scores and one for listener-rated scores - to understand the difference between identity and perception. If you’d like to test your gaydar, please do so by taking the survey here.
Click to expand a longer explanation.
Current Phase: Acoustic Analysis
We're getting comprehensive acoustic features from the recorded speech samples using our various tools. This includes fundamental frequency statistics, formant trajectories, spectral characteristics of fricatives and sibilants, rhythm and timing metrics, and voice quality measures.
Upcoming: Listener Perception Studies
We plan to have listeners rate how "gay" the voices sound, giving us a second prediction target alongside the self-reported sexuality scores. This will allow us to explore the potentially important distinction between sexual identity and how sexuality is perceived by others.
Dual Neural Network Approach
We'll train two separate neural networks: one trained on self-identified sexuality scores and another trained on listener-rated scores. Comparing these models will reveal whether the acoustic cues that predict self-identity are the same as those that inform listener perceptions, or if there are differences, for whatever reason if be.
An Update From Jan 1, 2026
Hey guys, it’s been a while! Welp, it’s been a bit of a wild ride – after securing 36 total recordings, I was told that our IRB (Institutional Review Board) actually told us to start over the project…
For a bit of context, every research project with human subjects involves an IRB that outlines what you can and cannot do (which is certainly super important if you’re going to be testing medicines on babies or something). In our case, our original IRB involved using participants under 18 as speakers. This was originally deemed okay because, at least in my and my mentor’s minds, we were studying the voice, and not the person, so the age was irrelevant.
Unfortunately, I got a call from my mentor late October as I was finishing up my first batches of neural network stuff. He basically told me the whole project had to be redone, as even though we’re mainly studying the voice, the sexuality was still being considered (and thus, human subject rules still applied). I know, after having spent an entire summer doing this, I’m just as upset as you are.
So now, we’re redoing the project. On the bright side, I’ve got a nice fancy audio recorder that’ll capture a little more auditory information than an iPhone’s voice memos. I think my mentor has given me 20ish recordings too, and hopefully we’ll be able to submit to LavLangs by mid-March. Sorry to disappoint but hey, I’m chugging along.
An Update From April 9, 2026
Good news — we actually have results! We’ve submitted some initial findings to Lavender Languages and Linguistics, a conference dedicated to language and sexuality research. Below I’ll share some of the most interesting things we found from our listener perception data, and you can see every plot here.
Quick refresher on the setup: 85 listeners rated 36 speakers on a 1–5 scale (1 = sounds very straight, 5 = sounds very gay), and we compare those ratings to the speakers’ own self-reported sexuality scores.
Can people actually tell?
The short answer: barely.
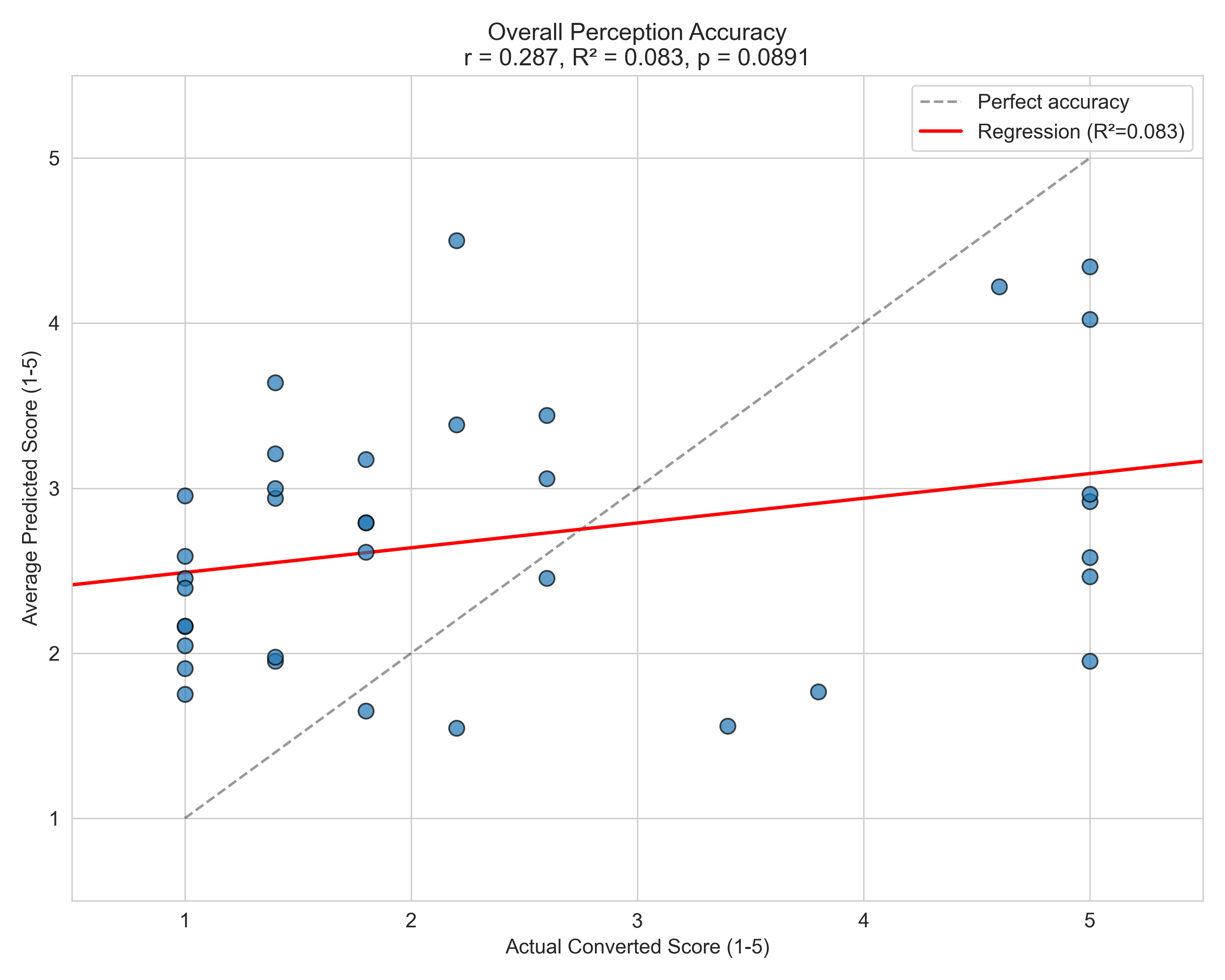
Overall perception accuracy comes in at r = 0.287, R² = 0.083, p = 0.089 — a weak, marginally significant positive correlation. The regression line is pretty flat. Listeners tend to cluster their guesses toward the middle of the scale regardless of a speaker’s actual sexuality, and the variance is enormous. There is some signal here, but it’s faint.
Signal Detection Theory (SDT) gives us another lens on this. SDT separates a listener’s sensitivity (can they actually tell gay from straight voices?) from their bias (do they lean toward calling things one way or the other?):
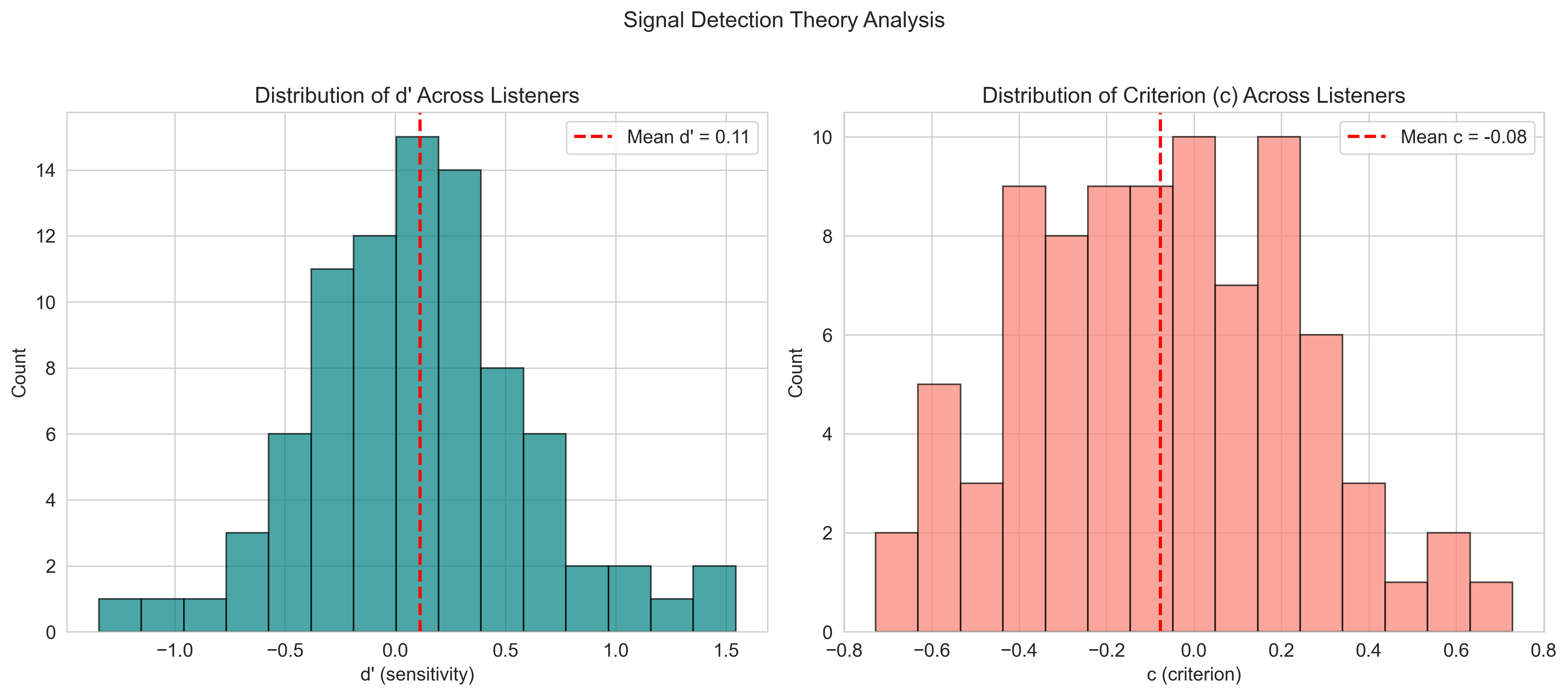
The mean d’ (sensitivity) across listeners is 0.11 — essentially at chance. Most listeners are barely better than random at picking up the “gay voice” from voice alone. The criterion c is slightly negative (−0.08), indicating a very mild tendency to rate voices as gay-sounding more liberally, but not dramatically so.
But here’s the twist: everyone agrees with each other
Despite performing near chance, listeners are remarkably consistent with one another:
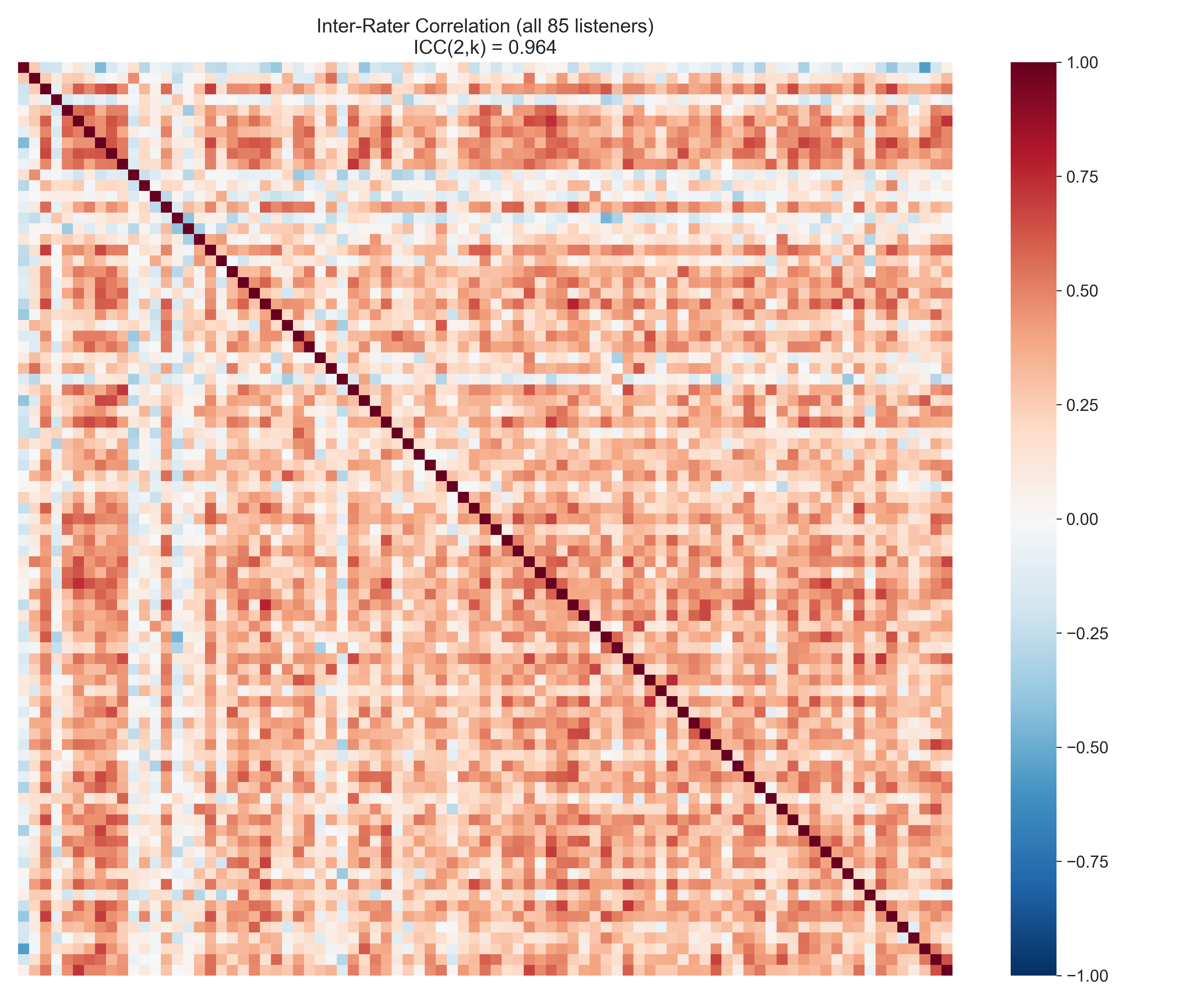
The inter-rater correlation matrix shows an ICC(2,k) = 0.964 across all 85 listeners — basically perfect reliability. When listeners rate a voice as gay-sounding, pretty much everyone agrees on that rating. They’re just wrong a lot of the time.
This is one of the most interesting findings we have. It suggests there’s a clear, shared cultural prototype of what “the gay voice” sounds like — a consistent perceptual category — but that prototype doesn’t map cleanly onto actual gay speakers. People know what they think a gay voice sounds like; they’re just not great at using it to identify real sexuality.
Some speakers are just easier to read than others
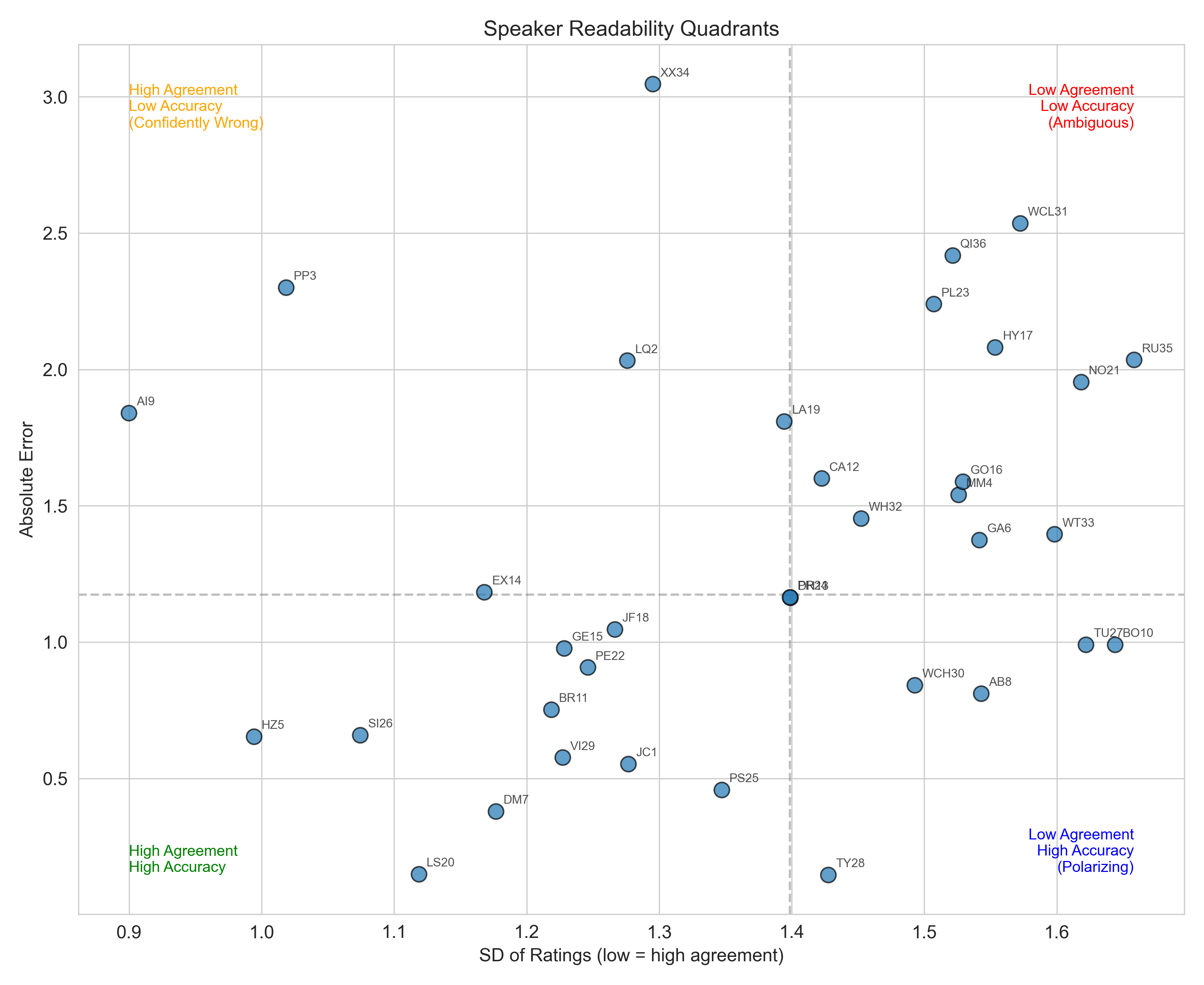
This is probably my favorite plot. Plotting each speaker by listener agreement (SD of ratings, x-axis — lower = more agreement) vs. prediction error (y-axis — lower = more accurate), we get four interesting speaker types:
- Bottom-left — High Agreement, High Accuracy: Easy-to-read voices. Everyone agrees, and everyone’s right.
- Top-left — High Agreement, Low Accuracy: “Confidently wrong” speakers. Everyone thinks the same thing, and everyone’s wrong. These are fascinating cases.
- Top-right — Low Agreement, Low Accuracy: Ambiguous speakers. Nobody agrees, and nobody’s right.
- Bottom-right — Low Agreement, High Accuracy: Polarizing speakers. Listeners disagree strongly, but when they do guess, they often land close to correct.
Do some listeners do better than others?
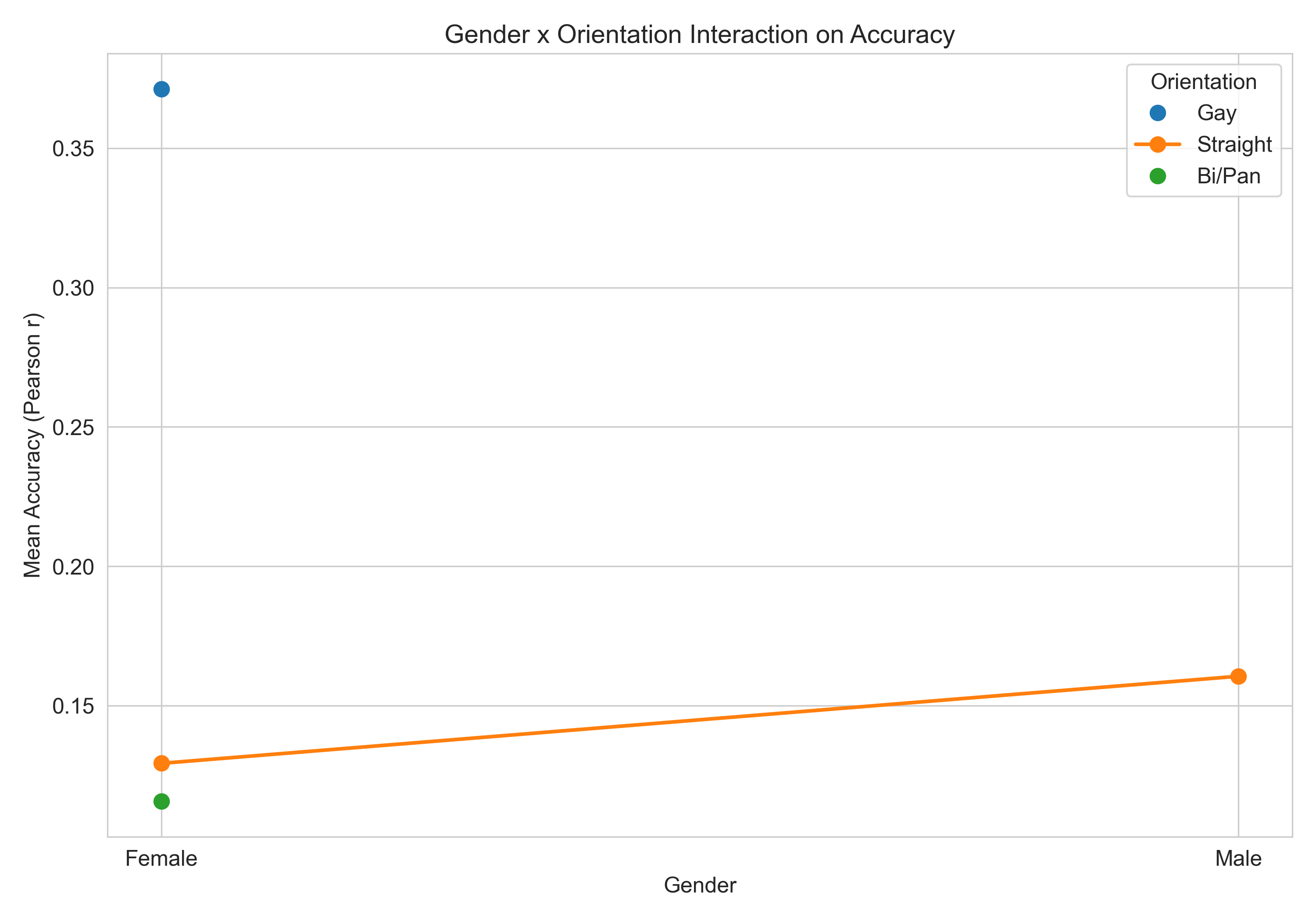
Gay/lesbian listeners appear to be considerably more accurate (r ≈ 0.37) than straight or bi/pan listeners (r ≈ 0.13–0.16). This aligns with prior literature suggesting ingroup familiarity may sharpen perception. That said — our gay/lesbian listener sample was only N=2, which is way too small to draw real conclusions from. Something worth testing with more listeners in the future.
What doesn’t seem to matter
We also looked at whether religiosity predicts rating bias — i.e., whether more religious listeners systematically rate voices as straighter or gayer:
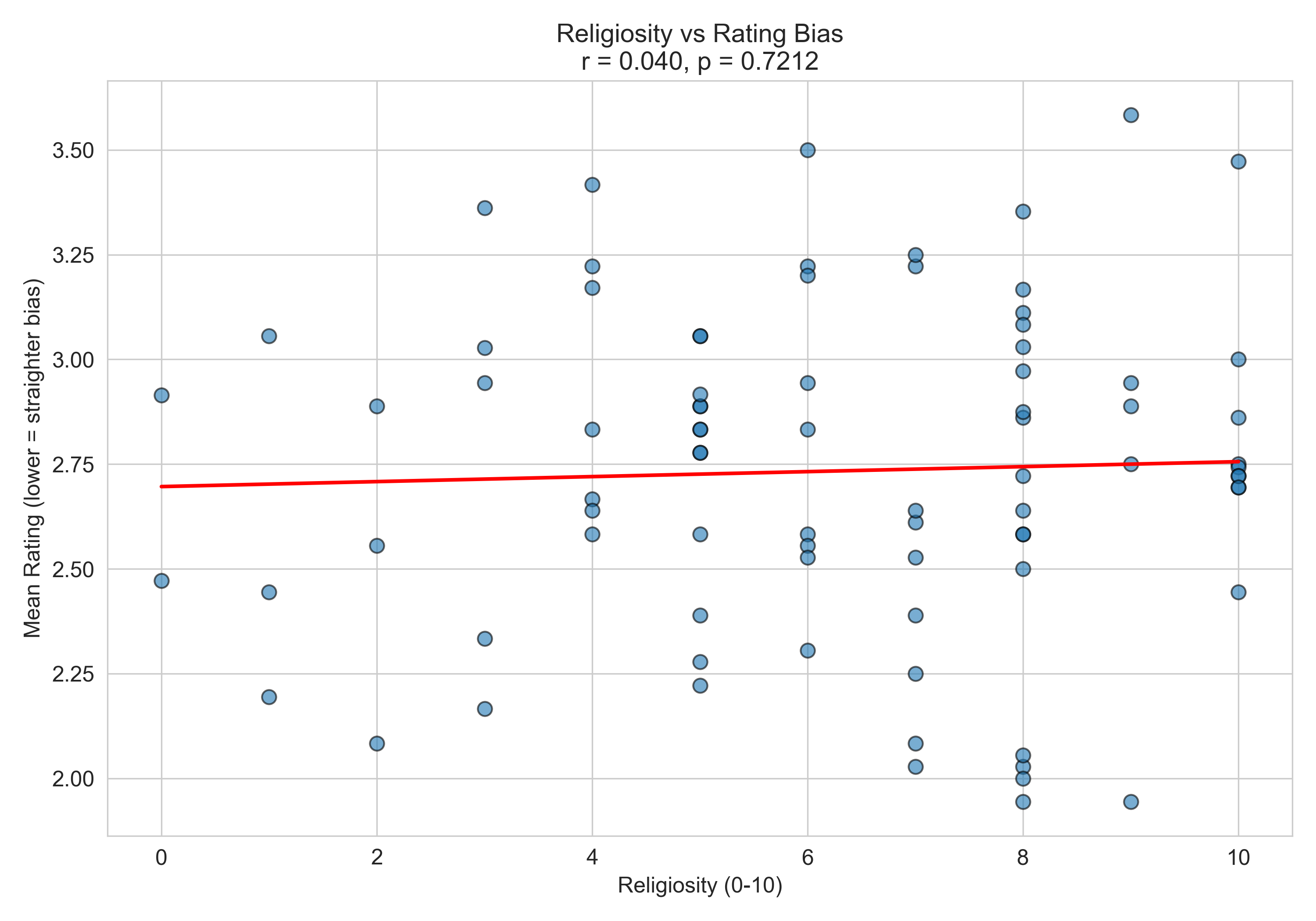
With r = 0.040 and p = 0.721, religiosity has essentially zero relationship with how listeners rate voices. Whatever individual differences are driving people to rate voices one way or another, it isn’t how religious they are.
A “perceived gayness” dimension exists — it just doesn’t track reality
Principal component analysis on the listener ratings reveals something interesting. PC1 — the single biggest axis of variation across all listeners, accounting for 30.9% of the variance — correlates with mean listener rating at r = 0.998:
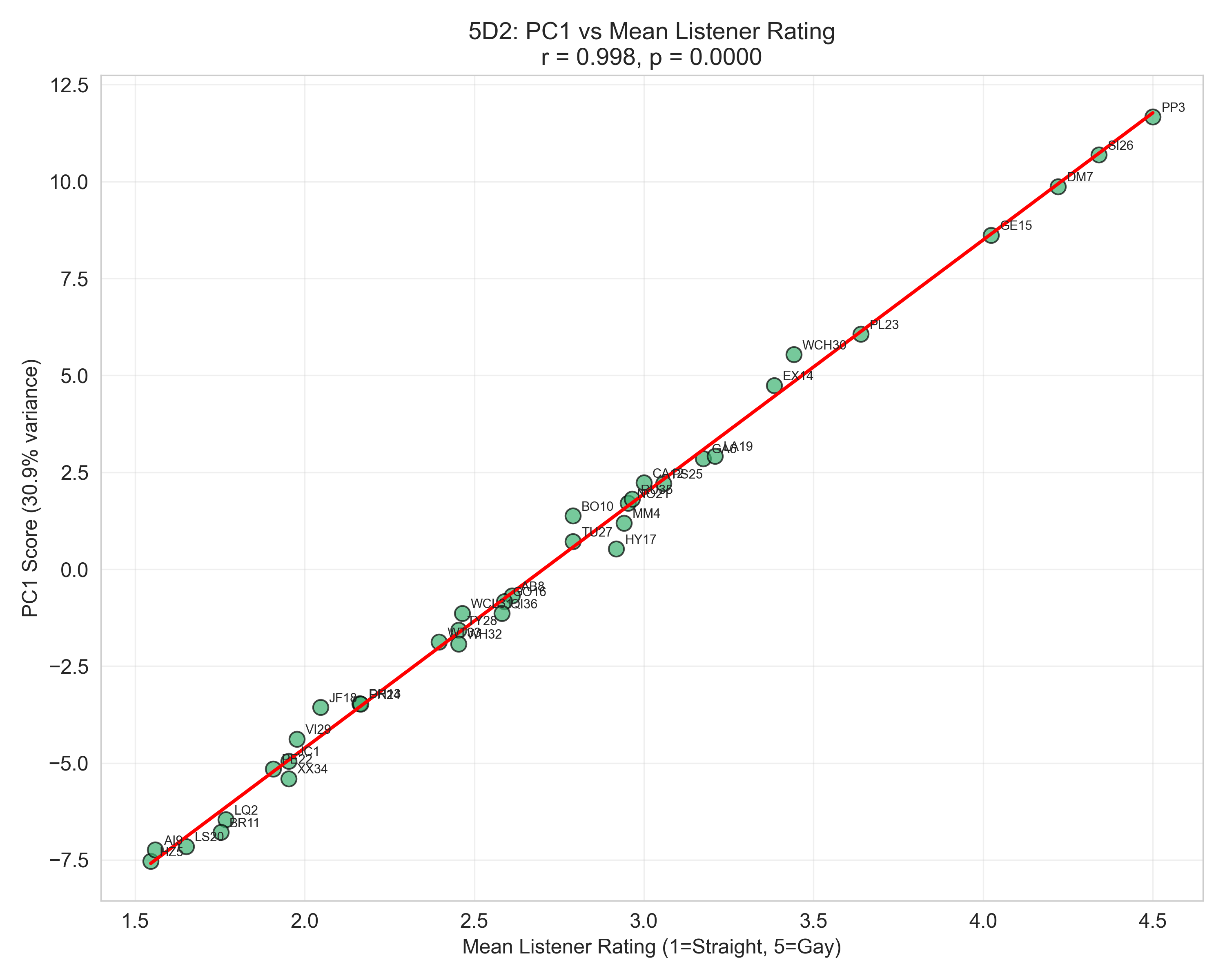
That’s essentially a perfect line. PC1 is, for all practical purposes, “how gay-sounding listeners collectively perceive this speaker.” It’s a clean summary of the shared perceptual dimension: the consistent cultural prototype.
Now here’s where it gets interesting. When you plot that same PC1 score against each speaker’s actual self-reported sexuality:
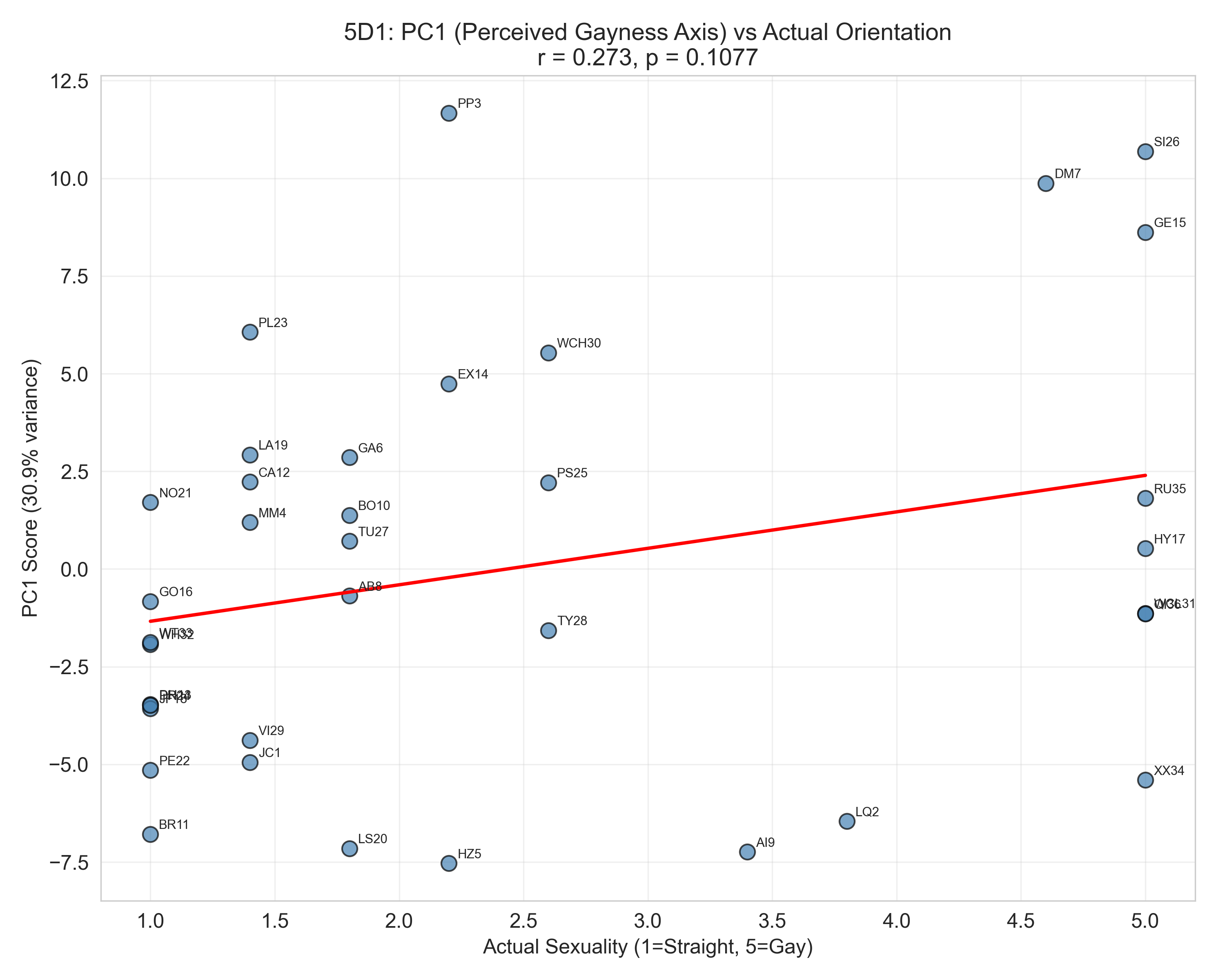
r = 0.273, p = 0.108 — weak and non-significant. The perceptual dimension that listeners share so reliably barely correlates with actual sexuality. Listeners are collectively measuring something with high precision, but that something isn’t the speaker’s self-reported identity.
Finally, you might expect that speakers at the extremes of that perceptual axis — voices listeners unanimously read as very gay or very straight — would at least be easier to get right. Not so:
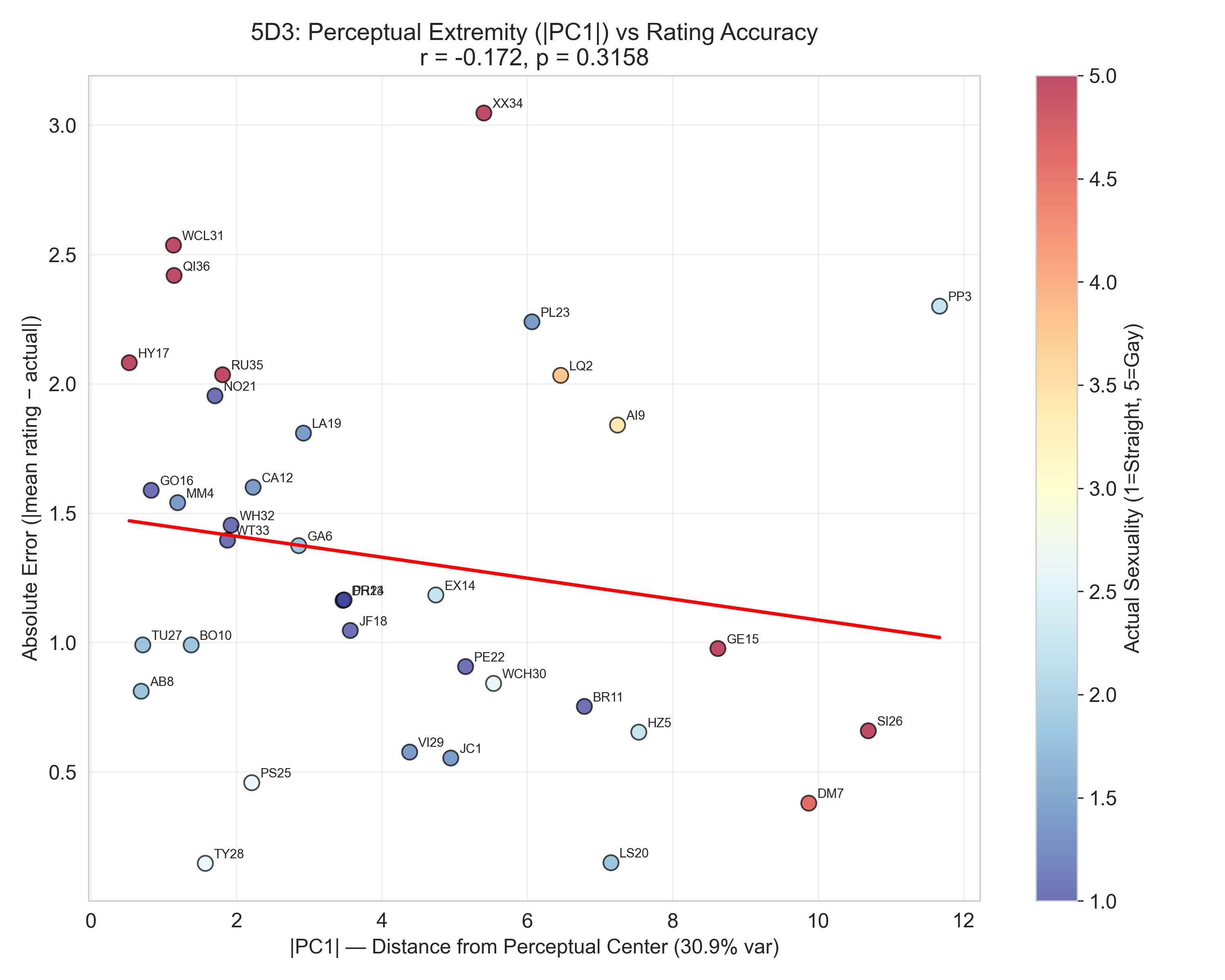
| Perceptual extremity ( | PC1 | ) has essentially no relationship with prediction error (r = −0.172, p = 0.316). A voice that listeners unanimously peg as “very gay sounding” is no more likely to actually be gay than one they’re ambivalent about. The confidence doesn’t translate to accuracy. |
The big picture takeaway: people largely can’t identify who’s actually gay from voice alone, but they’re strikingly consistent in their (often wrong) judgments — pointing to a shared cultural “gay voice” prototype that doesn’t perfectly reflect reality. The acoustic work is still ongoing, and we’ll be digging into what features drive these perceptions next.
Interested in seeing all of our analysis plots? Click here for the full plot gallery.