
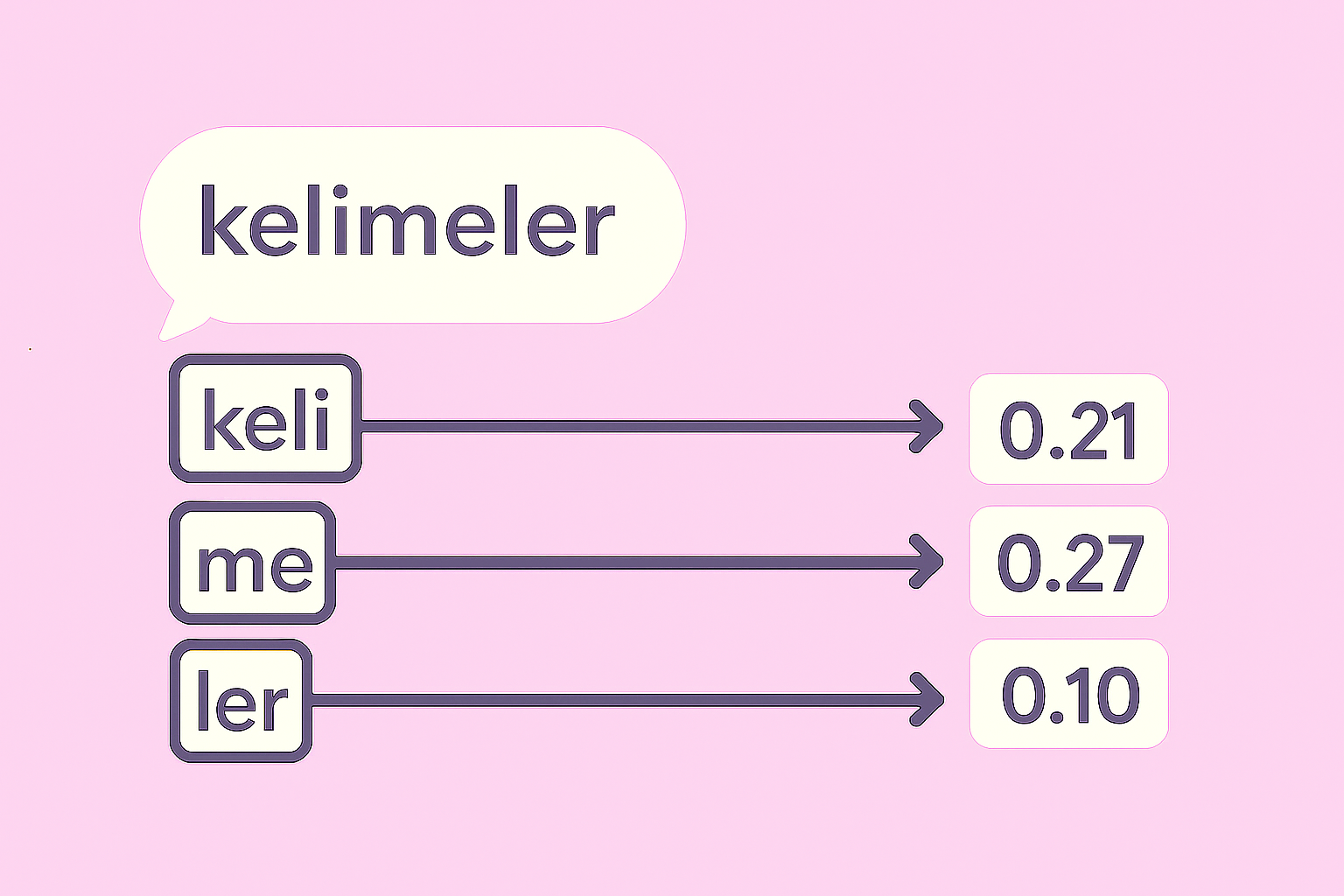
Tokenization in Turkish and Finnish
Scraped text in Turkish and Finnish to study tokenization in agglutinative languages. Evaluated using Word2Vec and Named Entity Recognition sets.
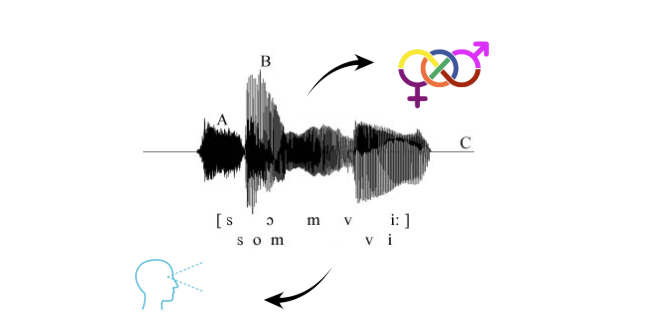
A Neural Network Informed Study on the Gay Voice
An ongoing project with CUNY Queens on identifying linguistic features that correspond with both self-reported sexuality and listener-perceived sexuality in Gen Z youth.
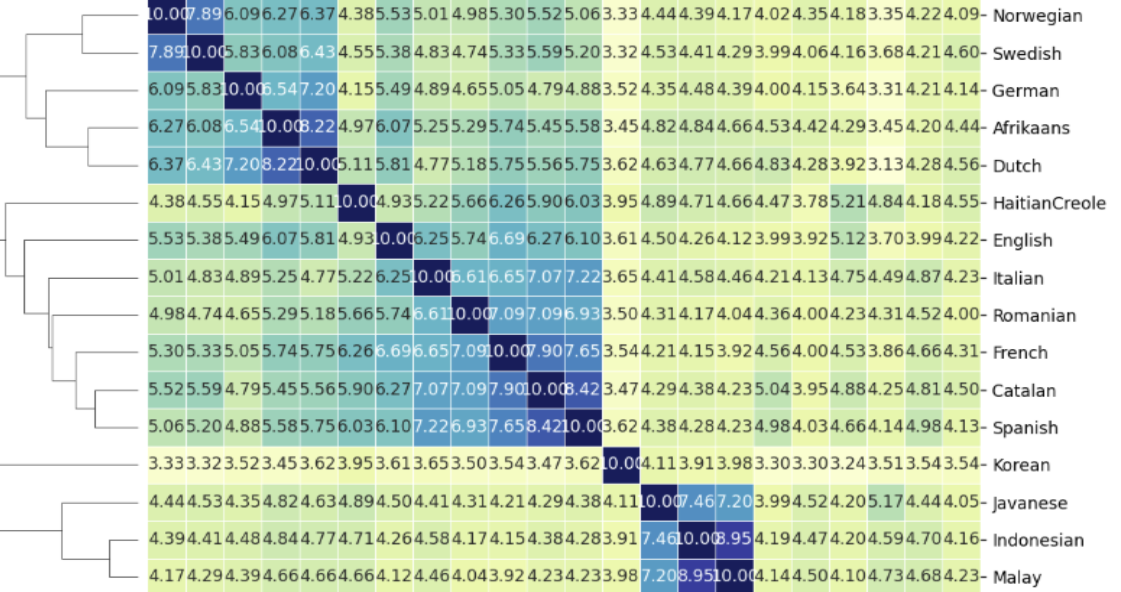
Generating Language Families using Word Similarity
2024 Summer Project for Tufts Engineering with AI Camp: Using the UDHR, ran a comparison using Levenshtein Distance to "classify" language families.

AI-Powered Crosswalk Safety Monitoring System
Built a dual-model computer vision system using Raspberry Pi 5 and IMX500 to detect pedestrians and vehicles at a dangerous crosswalk. Solved real tracking problems like "ghost cars" and distant pedestrian detection.