
For this project, I tried to explore reverse-engineering language families according to the similarity of the words. This was done by using Levenshtein distance.
So uh… what is a language family?
TLDR: Language families are groups of languages that are related through a common ancestor (a language that was spoken before, that diverged to create new languages). Some examples include Romance Languages, Germanic Languages, and Semitic Languages.

Click to expand a longer explanation.
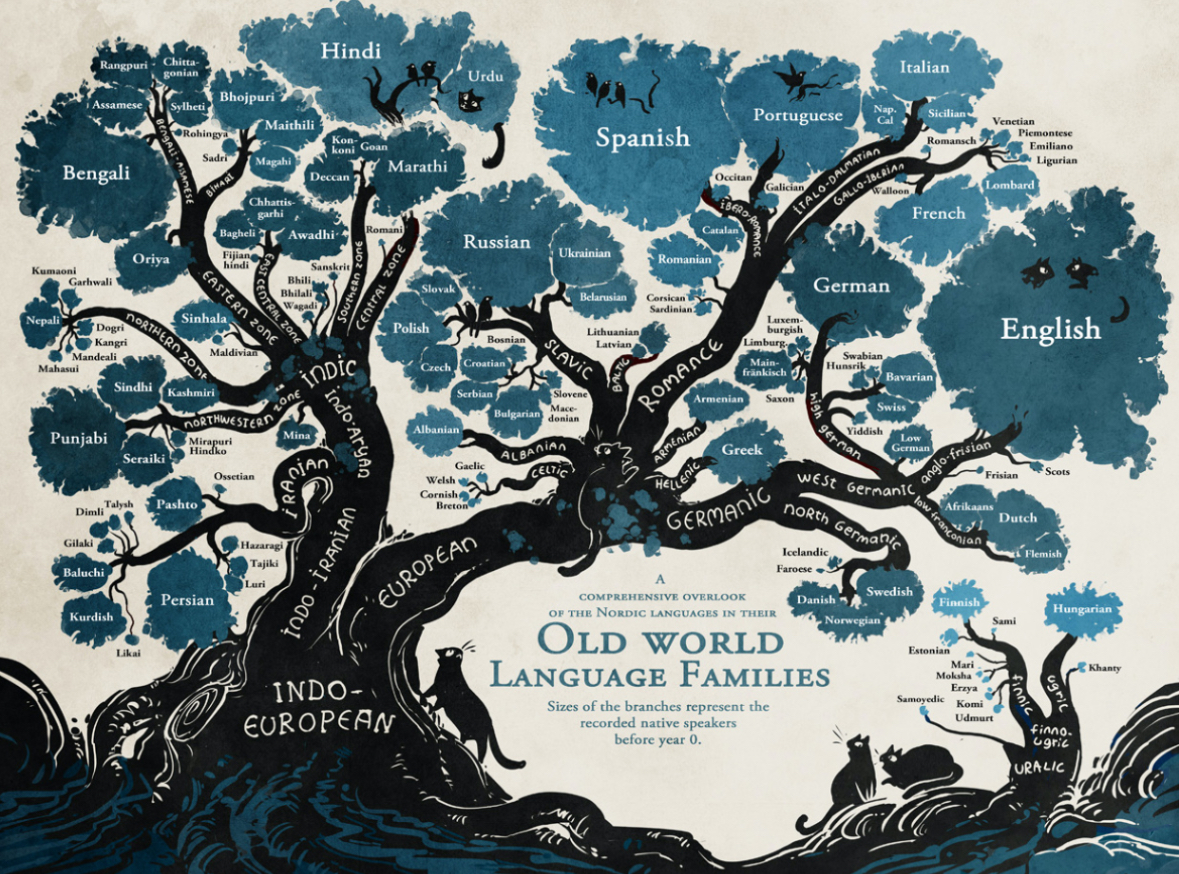
The image above is an artist's rendering of the Indo-European language family. As you can see, it includes many of the world's most spoken languages such as English, Spanish, Hindi, Bengali, French, Russian, and Persian. Yup, all of these languages had the same common ancestor, which is why they're all classified under one family/tree.
For Indo-European, the big leap happened in 1786, when Sir William Jones was looking at Sanskrit (an ancestor of Hindi) and comparing them to other classical European languages, where he discovered that a lot of vocabulary was similar. For example:
| English | Latin | Sanskrit |
| donation | dōnum | दान (dāna) |
| new | novus | नव (nava) |
| interior | intra | अन्तर (antara) |
| mother | māter | मातृ (mātr) |
Of course, determining language families is not so easy as just comparing words. Taking English as an example, we took tons of vocabulary from the French, but we're actually a Germanic family language. You can take a looksie at what English would've looked like without French influence: it's called Anglish!
Unfortunately, it's hard to classify language families at times. Theories come and go on language families, and they're always complicated by actual history. For the case of English, the reason we had so much French influence was because of the Norman Conquest of England. An example of where trying to use history to back-track language spreading failed is the Altaic language family, a theory that was supported by the nomadic migration of the peoples in the areas that "Altaic" languages were spoken. Unfortunately, the similarities that the languages shared were largely coincidental, and Altaic is no longer supported.

So you said that determining language families aren’t done by just comparing words. Levenshtein distance is just comparing words… no?
TLDR: Woah, shots fired, you got me there! I was just messing around with words to try and make families of lexical similarity! You’re right that Levenshtein distance looks at words, and there’s a lot of limitations with what I was doing! Guess a five-day project can’t be too deep after all.
Click to expand a longer explanation.
So to start off, a quick review of what Levenshtein distance is!

Yeah, I know. Don't worry though, despite this math looking really complicated, it's actually pretty simple. Levenshtein distance is basically a measurement of how many letters you have to substitute, add, or delete to get from word a to word b. An example: the Levenshtein distance between the words "Frank" and "Tank" is two! Substitute "r" for "T" (+1 to distance), and delete "F" from "FTank" (+1 to distance). This is often used in spell-check algorithms: if a word isn't recognized in the spell-checker's dictionary, it'll ask you if you meant words that are a small Levenshtein distance away. It's also used in... drumroll please... comparative linguistics! Because languages with a shared common ancestor should have tons of cognates with each other, Levenshtein distance becomes a great way to measure the linguistic distance between two languages!

I mean... come on! Isn't that hilarious? Dutch is so similar to English! And best of all, we can look at the Levenshtein distance to try and quantify that distance. We hebben een serieus probleem -- We have a serious problem! The Levenshtein distance between these two sentences is tiny: 0 from we to we, 4 for hebben to have, 3 from een to a, 1 from serieus to serious, 1 from probleem to problem. (If you're curious, the rest translates to: "with the political developments regarding the coercion law, and I hope that this can be resolved in the coming days." Not as similar as we hebben een serieus probleem lol!) Anyways, using this, I tried to compare all sorts of different languages to each other.
Sure, I guess that makes sense. So why use the Universal Declaration of Human Rights?
TLDR: I was looking for a document that was well-translated and available for a whole bunch of different languages, from high to low resource. The UDHR checks all of those boxes, as it’s kind of a go-to for providing examples of a language.
Click to expand a longer explanation.
So as of July 14, 2025, the UDHR is available in 570 languages. That alone is great when it comes to coverage of a ton of diverse languages. However, not only is it extensively translated, but the text is aligned sentence by sentence. That means that each sentence should say the same thing, no matter what language. This is really difficult to do! Think about it, I could say: "Jack ate an apple because his mom didn't make him lunch;" and maybe a translation would be along the lines of: "His mom didn't make him lunch, so Jack ate an apple." Same meaning, different order, hard to compare! Even worse, a translation could break it up into two sentences (no recursion pirahã, hahã!) "Jack's mom didn't make him lunch. Jack was hungry. Jack ate an apple." Now we've got three sentences instead of one, and it's hard to compare across languages which word specifically means what!"
Not only that, but it also covers concepts like freedom, dignity, rights, and obligations -- all abstract, culturally sensitive concepts that help map languages by semantic accuracy -- some languages could represent certain things a certain way, even when genetically related. And because it's so ethically and legally important worldwide, translators put extra care in ensuring its accuracy, even in low-resource languages. And for low-resource languages, sometimes the UDHR is the only available aligned text with other major world languages.
Ok, got it. So what did you do to create language families?
-
I calculated pairwise similarity scores between languages by using Levenshtein distance.
-
I converted them into a standardized similarity matrix, with 10 (0 Levenshtein distance, aka English vs English, aka perfect score) being the highest similarity score.
-
I used SciPy’s hierarchical clustering (linkage) to get clustering trees.
-
I passed that to Seaborn’s clustermap, which drew a heatmap of standardized similarity, and visualized the “trees” corresponding to the clustering order.
So where can I see the code and the images you generated after a couple of runs?
Oh come on, I’m kind of embarassed. This stuff is pretty garbage. If you really want to check out what I used for this project, you can find it here. Seriously, I’m warning you: I grinded this out with a lot of help of AI and a few days of caffeine fueled frenzy. Don’t expect much. In fact, don’t expect anything! You will laugh at the graphs I generated, because I’m telling you, some of them are total garbage. I also didn’t know how to use GitHub back then, so you’re going to have to come through some files…
It sounds like you’re talking down this project a lot. What can be improved?
TLDR: Levenshtein distance is not enough. It doesn’t account for syntactic difference, phonological difference, difference in writing systems, and a whole bunch of other stuff.
Click to expand a longer explanation.
So the first thing that I talked about earlier, is that language families aren't about surface forms, they're about historical descent. Two unrelated languages (English and French) may borrow a ton of vocabulary from each other and look more similar than they actually are.
The second thing that really kills this project is Writing system bias. Take Serbian and Croatian for example -- "Human rights" in Serbian is "Људска права," while in Croatian it's "Ljudska prava." Looks really different, right? Well surprise surprise, they're actually pronounced the same. While in my project I tried to mitigate this by using online text converters from their script to latin script, it's obviously not a sustainable nor good solution, as each language can use a script differently. Another example: Haitian Creole and French -- they should be super related, but since their orthography is different, their Levenshtein distance is inflated. To really make this project shine, it would've been cool to convert each language's writing to IPA.
Again, I mentioned this before, but you have to take into account morphology, word order, and grammar. If some language uses Subject-Verb-Object ordering, and some other language uses flexible word order, even if their vocabulary is similar, their Levenshtein distance is going to be huge because there's going to be tons of substitutions. Even worse, some languages still smash multiple words into one, making Levenshtein distance an even more difficult method of comparing linguistic similarity.
Thank you to Victor, my roommate, for putting up with my late-night grinds and keeping me entertained with your Roblox gambling sessions. Love you pookie 🥰🥰